با درود فراوان، این پست ادامه پست قبلی یعنی پیاده سازی یک مدل رگرسیون خطی با الگوریتم Stochastic Gradient Descent از پایه با پایتون می باشد. در این قسمت من در ابتدا به توضیح مختصری از الگوریتم Logistic Regression میپردازم و در ادامه این الگوریتم را از پایه با پایتون پیاده سازی خواهیم کرد.
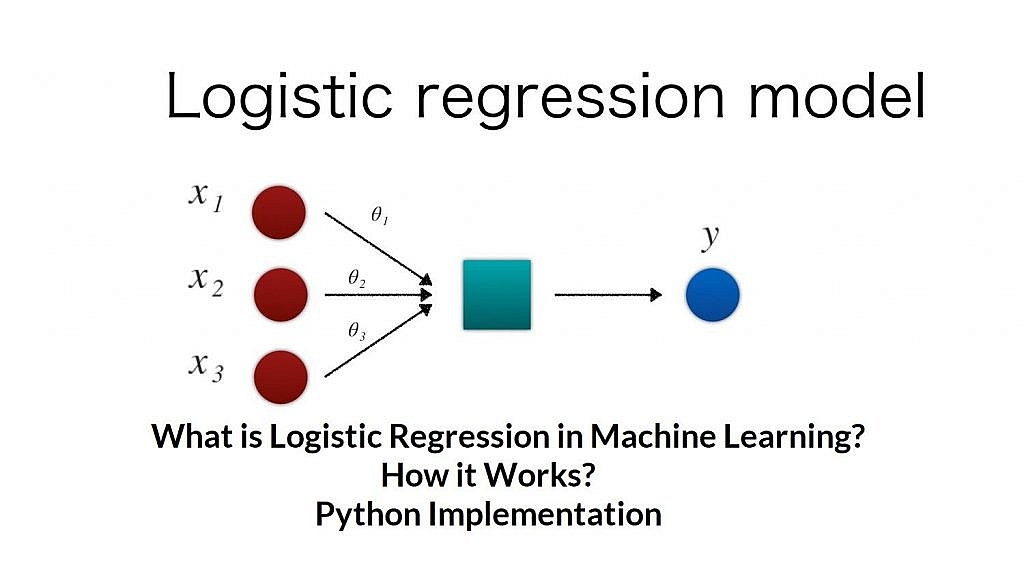
Logistic Regression
بر خلاف دو الگوریتم قبلی که متغیر وابسته یعنی Y میتوانست هر مقداری بصورت نا محدود در یک فضای پیوسته داشته باشد، در اینجا این متغیر باید چند مقدار محدود و گسسته یا به اصطلاح Categorical داشته باشد. اگر متغیر وابسته تنها دو مقدار داشته باشد، به آن Binary Logistic Regression میگوند. اگر فرمول رگرسیون خطی را به خاطر داشته باشید خروجی آن جمع وزن دار ورودی ها بود. اما Logistic Regression یک حالت کلی تر از رگرسیون خطی است یعنی خروجی آن بعد از محاسبه جمع وزن دار ورودی ها به یک تابع برای نگاشت آن به صفر و یک داده میشود و مقدار نگاشت شده به خروجی میرود. به تابعی که هر مقدار عدد حقیقی را به صفر و یک نگاشت میکند تابع فعال ساز یا Activation Function میگوند. هر تابع فعال سازی که این خصوصیت را داشته باشد قابل استفاده است اما ما در اینجا از تابع سیگموید استفاده میکنیم که نمودار آن را در زیر گذاشته ام.

همانطور که میبینید مقدار این تابع همیشه بین صفر و یک و در X = 0 برابر با 0.5 است. بنابراین میتوان سر حد احتمال برای هر دسته را 0.5 در نظر گرفت یعنی اگر احتمال ورودی ها کمتر از نیم شد مربوط به کلاس صفر و اگر بیشتر از نیم شد مربوط به کلاس یک است. اگر به خاطر داشته باشید در رگرسیون خطی مقدار Ŷ برابر با XW بود.
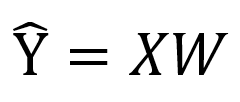
اگر تابع سیگموید را روی مقدار بدست آمده اعمال کنیم خروجی Logistic Regression بدست می آید.
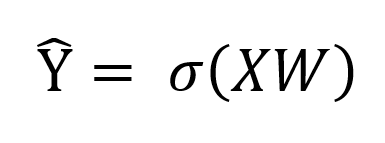
فرمول تابع سیگموید نیز در زیر نوشته شده است.
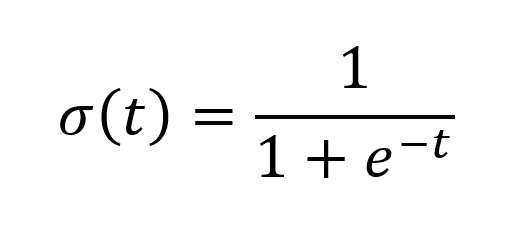
اگر این دو تابع را در هم ادغام کنیم به تابع زیر میرسیم.
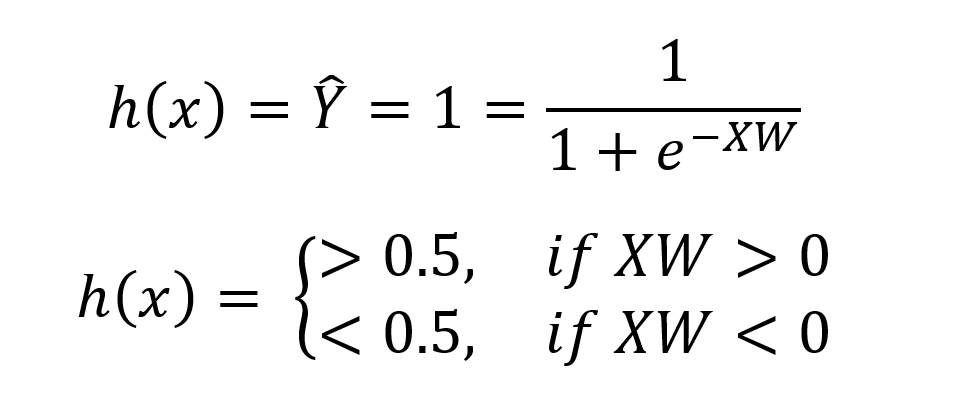
اگر حاصل این جمع وزن دار بیشتر از صفر باشه کلاس مربوط به آن یک و اگر کمتر از صفر باشد کلاس آن صفر است. مانند رگرسیون خطی نیز ما باید یک تابع هزینه معرفی کرده و سعی بر کمینه کردن آن داشته باشیم. تابع هزینه مورد نظر برای یک نمونه از دیتا بصورت زیر معرفی میشود.

برای هر چه
به سمت یک میل کند نمودار آن نیز به سمت صفر و هر چه به سمت صفر میل کند نمودار آن به سمت بی نهایت میرود. همینطور برای
نیز هر چه
به سمت یک میل کند نمودار آن به سمت صفر و هر چه به سمت صفر میل کند نمودار آن بی نهایت میشود.
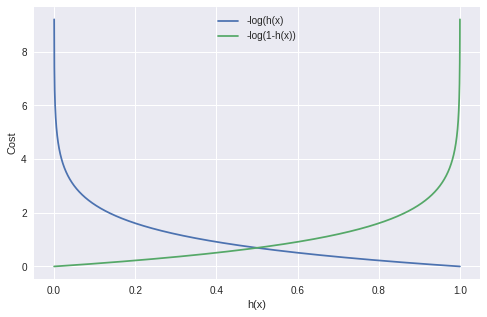
اگر هر دو معادله بالا را با هم ترکیب کنیم به معادله زیر میرسیم.

اگر بخواهیم هزینه را برای تمام دیتا هایمان بدست بیاوریم باید برای تک تک آن ها این فرمول را حساب کرده و میانگین آن ها را بدست بیاوریم.
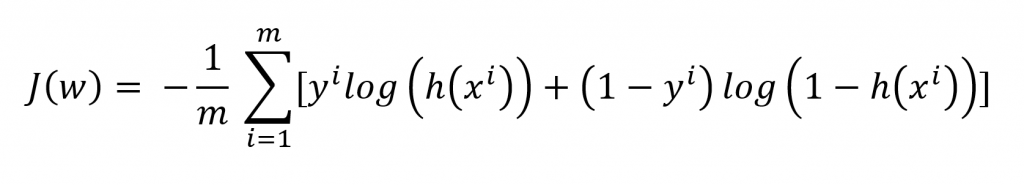
در اینجا m تعداد داده ها می باشد. برای کمینه کردن این معادله نیز از Gradient Descent کمک میگیریم که فرمولی شبیه آن چه در رگرسیون خطی دیدید دارد.
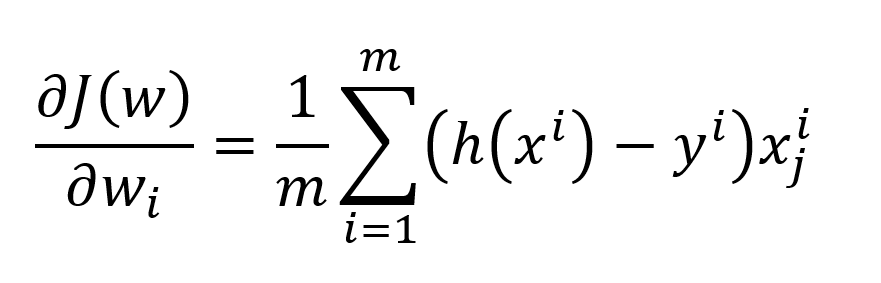
برای آپدیت کردن هر وزن نیز از فرمول زیر استفاده میشود.
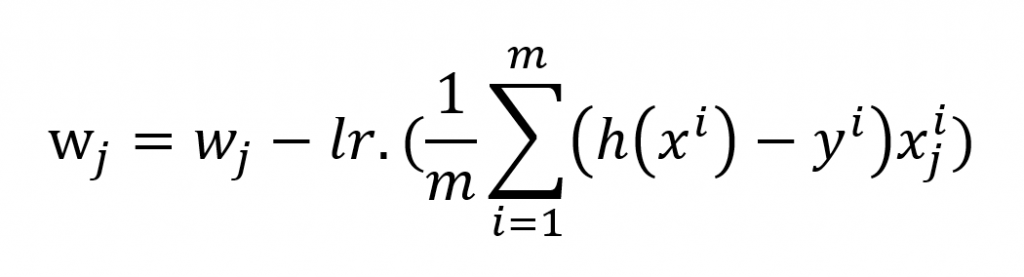
از آنجایی که دیتاستی که استفاده میکنیم تنها دو مقدار/ویژگی در هر نمونه از ورودی وجود دارد، بعد از اجرای الگوریتم و یاد گرفتن پارامتر ها معادله خطی ما بصورت زیر است.
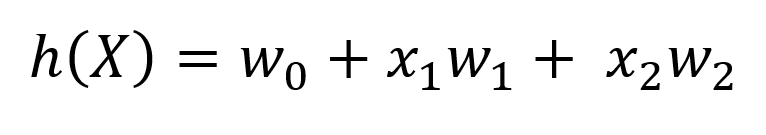
اگر بخواهیم بحث را خلاصه کنیم معادله خط تصمیم گیری یا همان Decision Boundary از فرمول زیر بدست می آید.
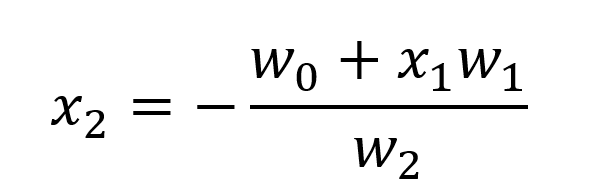
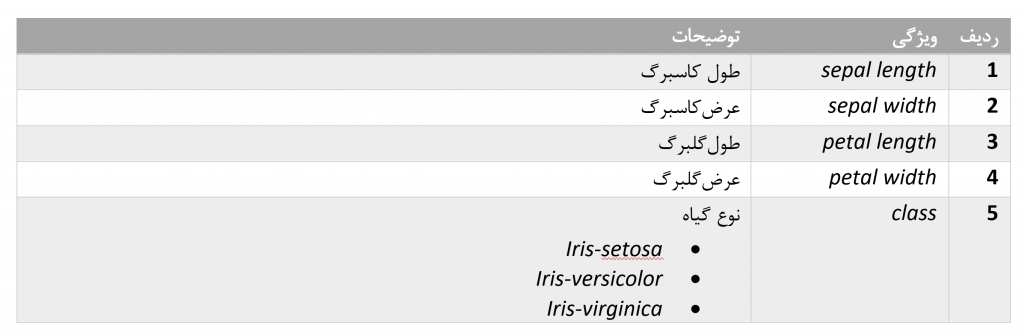
این همه توضیحات لازم و بسیار مختصر درباره این الگوریتم بود. برای این آموزش ما از دیتاست IRIS استفاده خواهیم کرد که دو تا از چهار مقدار در هر نمونه از این دیتاست را حذف خواهیم کرد یعنی ماتریس ویژگی های ما دو ستونه است و یکی از دسته ها یا همان Category ها را نیز جهت استفاده از این دیتاست در الگوریتم Binary Logistic Regression حذف خواهیم کرد. ستون یک تا چهار ستون ویژگی هاست که ما ستون های 3 و 4 را حذف میکنیم و ستون پنجم ستون کلاس هاست که ما ردیف های مربوط به کلاس Iris-versicolor را حذف خواهیم کرد. و باقی دو کلاس را به صفر و یک مپ میکنیم زیرا مقدار ستون کلاس بصورت رشته است و ما با عدد کار میکنیم. در زیر نمایی کلی به همراه توضیحاتی درباره هر ویژگی ارائه کرده ایم.
پیاده سازی
در این پیاده سازی ما از زبان پایتون و کتاب خانه های Numpy، Pandas و Matplotlib برای خواندن فایل ها، انجام پیش پردازش ها و محاسبات و رسم نمودار ها استفاده شده است. داده هایی که این جا استفاده میشود از دیتاست معروف Iris است که در قسمت قبلی توضیح دادیم. در ادامه به تشریح توابع نوشته شده که مربوط به بخش اصلی الگوریتم هستند میپردازیم. این کد ها را متاسفانه به دلیل کمبود وقت خیلی تمیز نزدم، بهبود کد به عهده خودتون 🙂
load_data

این تابع Iris.Data را بوسیله کتاب خانه Pandas درون برنامه وارد و پس از حذف دو ستون و حذف کلاس Iris_versicolor، داده ها را به دسته های Train و Test به کمک کتاب خانه Sklearn و با نرخ 80 به 20 بر میگرداند. آدرس فایل را در ورودی تابع pd.read_csv وارد نمایید.
Normalization

این تابع داده ها را بین صفر و یک نرمال میکند.
init_weights

این تابع وزن های با مقادیر رندم برای شروع الگوریتم، تولید میکند.
Sigmoid

تابع سیگمویدی که توضیح داده شد را در اینجا پیاده سازی کرده ایم.
compute_loss

این تابع نیز برای محاسبه Cost طبق همان فرمول ارائه شده استفاده می شود.
update_weight

این تابع برای محاسبه بخش مربوط به معادله آپدیت هزینه استفاده میشود.
update_bias

بایاس نیز مانند وزن ها آپدیت میکنیم.
Mse

این تابع برای محاسبه Mean Square Error بر روی مقادیر پیش بینی شده و مقادیر واقعی استفاده میشود. ورودی اول مقدار های پیش بینی شده و ورودی دوم مقدار های واقعی هستند.
Predict

این تابع برای پیشبینی روی ورودی های جدید استفاده میشود؛ مطابق با فرمولی که ارائه شد.
Decision_boundary

این تابع معادله خط Decision Boundary را پیاده سازی میکند.
Train

در این تابع بر اساس فرمول های شرح داده شده، مدل آموزش داده میشود.
پارامتر ها
برای آموزش ما چند پارامتر را برای تنظیمات مدل تعیین کرده ایم.
- Epochs : این مقدار تعیین کننده تعداد تکرار و دفعات اجرای الگوریتم می باشد که ما 10000 انتخاب کرده ایم.
- Lr : این همان نرخ یاد گیری است که ما 0.02 انتخاب کرده ایم.
نتیجه نهایی
بعد از اجرای الگوریتم بر روی داده ها به نکته ای دست می یابیم. اگر داده ها را بین صفر و یک نرمال کنیم مدل در یادگیری داده ها دقیق نمیشود و خطای MSE زیادی دارد. اما اگر نرمال سازی انجام نشود مدل به خوبی داده ها را یاد میگیرد و MSE کمتری دارد. مقدار نرخ یادگیری و تعداد epoch ها نیز بسیار در همگرا شدن مدل مهم است.
نتایج با انجام نرمال سازی
نمودار خط دسته بندی و توزیع داده های Train:
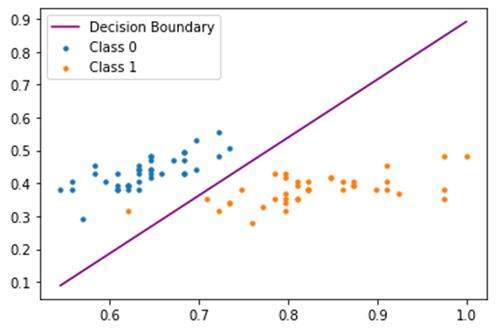
نمودار خط دسته بندی و توزیع داده های Test:
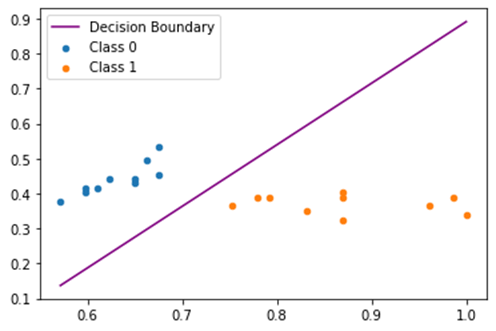
خطای MSE روی داده های Test و Train:
MSE Train = 0.1263218557144464
MSE Test = 0.10536628536297152
وزن های یاد گرفته شده به ترتیب از چپ : بایاس یا همان ،
و
[-1.41063747, 3.79707562, -6.25419372]
نتایج بدون انجام نرمال سازی
نمودار خط دسته بندی و توزیع داده های Train:

نمودار خط دسته بندی و توزیع داده های Test:
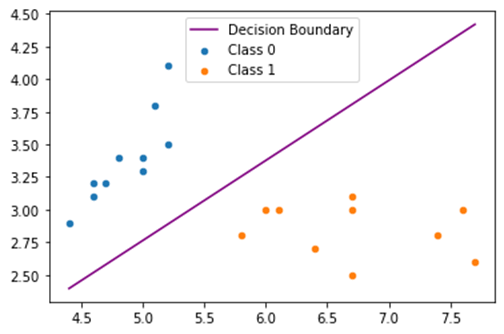
خطای MSE روی داده های Test و Train:
MSE Train = 0.012268323617948985
MSE Test = 0.0010944553649248978
وزن های یاد گرفته شده به ترتیب از چپ : بایاس یا همان ،
و
[-1.29405614, 3.79664167, -6.28995596]
برای دانلود فایل کد ها و دیتاست ها اینجا را کلیک کنید. برای رفتن به آموزش قبلی اینجا را کلیک کنید.
امیدوارم این آموزش برای شما مفید بوده باشد. پیشنهاد میکنم که در تمرین ها و پروژه های درسی این کد ها را کپی نکنید چون انسان های زرنگ دیگری نیز وجود دارند.
همچنین میتوانید با تغییر دادن پارامتر ها الگوریتم را تست کنید و نتایج را مقایسه کنید تا درک بهتری از آن پیدا کنید.
خوب و خوش باشید.