
با درود فراوان، این پست ادامه پست قبلی یعنی پیاده سازی یک مدل Closed Form Linear Regression از پایه با پایتون می باشد. در این سری آموزش ما قصد داریم الگوریتم رگرسیون خطی را بوسیله الگوریتم بهینه سازی Gradient Descent پیاده سازی کنیم. در ابتدا توضیح مختصری درباره این الگوریتم میدهیم و بعد به پیاده سازی آن خواهیم پرداخت. اگر با این الگوریتم ها آشنایی ندارید میتوانید برای یاد گیری بیشتر به کتاب هایی نظیر Elements of Statistical Learning یا کتاب Pattern Recognition and Machine Learning از کریستوفر بیشاپ مراجعه کنید.
Stochastic Gradient Descent Linear Regression
همانطور که توضیح دادیم رگرسیون در مبحث یادگیری ماشین، یک الگوریتم نظارت شده به حساب می آید و گفتیم که به طور کلی به دو روش مدل های رگرسیون خطی استفاده می شود. روش اول Closed Form بود که توضیح دادیم و پیاده سازی کردم و روش دوم همین روش می باشد.
سوالی که اینجا مطرح میشود این است که چرا از Gradient Descent استفاده کنیم وقتی فرمول Closed Form وجود دارد؟ این سوال دو جواب دارد.
- برای بعضی مسائل رگرسیون غیر خطی، راه حل Closed Form وجود ندارد.
- حتی برای رگرسیون خطی هم بعضی مواقع استفاده از Closed Form مناسب نیست زیرا ممکن است ورودی ها خیلی بزرگ باشند و یا ماتریس Sparse باشد. برای همین انجام محاسبات در این راه حل می تواند گران باشد.
الگوریتم Gradient Descent بطور کلی یک الگوریتم بهینه سازی تلقی میشود و هدف آن حداقل کردن یک تابع هزینه است. از لحاظ محاسباتی نیز ارزان است.
دو نمونه یا بهتر است بگوییم سه نمونه Gradient Descent داریم.
- Batch Gradient Descent : در این روش در هر epoch از کل دیتا ها بصورت یکجا برای محاسبه پارامتر ها استفاده میشود.
- Stochastic Gradient Descent : این روش برای داده های حجیم مناسب است که آوردن همه آن ها بصورت یکجا در رم و انجام محاسبات منطقی نیست. برای همین در هر epoch، محاسبات بر روی یک نمونه از داده انجام شده و پارامتر ها آپدیت میشوند.
- Mini Batch Gradient Descent : اگر رم کافی برای آوردن بخشی از دیتا ها در هر epoch در رم دارید میتوانید از این روش استفاده کنید.
کد نوشته شده در این بخش از هر سه روش قابل بهره گیری هست. در اینجا تابع هزینه ما تابع Mean Square Error هست و گرادیان ما مشتق این تابع بر حسب هر w در ماتریس W است که فرمول آن را در زیر میبینیم.
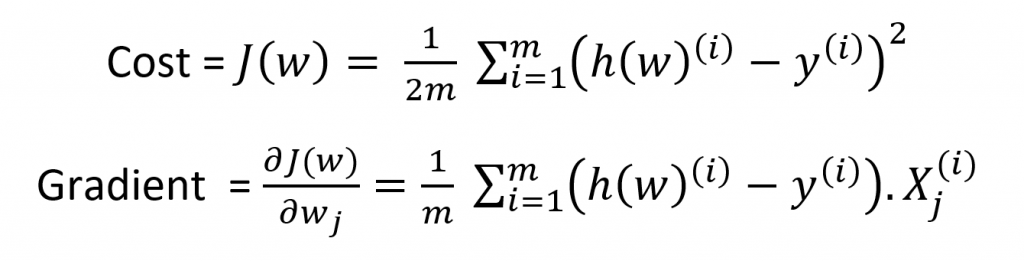
برای آپدیت کردن هر وزن نیز از فرمول زیر استفاده میشود.

متغیر lr همان نرخ یاد گیری یا Learning Rate می باشد که عددی بین صفر و یک انتخاب میکنیم. بعد از ساخت مدل و آموزش آن برای انجام پیش بینی روی داده های جدید از فرمول زیر استفاده میکنیم.
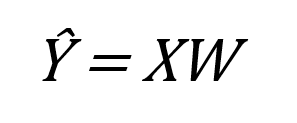
پیاده سازی
در این پیاده سازی ما از زبان پایتون و کتاب خانه های Numpy، Pandas و Matplotlib برای خواندن فایل ها، انجام پیش پردازش ها و محاسبات و رسم نمودار ها استفاده شده است. داده هایی که این جا استفاده میشود یکسری داده های مصنوعی می باشد که تنها یک متغیر مستقل دارد یعنی بردار x ما تک ستونه است. در ادامه به تشریح توابع نوشته شده که مربوط به بخش اصلی الگوریتم هستند میپردازیم. این کد ها را متاسفانه به دلیل کمبود وقت خیلی تمیز نزدم، بهبود کد به عهده خودتون 🙂
load_data

این تابع دو فایل CSV داده های Train و Test را بوسیله کتاب خانه Pandas درون برنامه وارد و بر میگرداند. آدرس فایل ها در ورودی تابع pd.read_csv وارد نمایید.
Normalization

این تابع مقدار متغیر های مستقل را بین صفر و یک نرمال میکند.
prepare_data

این تابع متغیر های مستقل و غیر مستقل را از برای داده های Train و Test جدا کرده و بر میگرداند.
batching_data

در این تابع از کل دیتا ها بصورت shuffle شده دسته هایی از داده به سایز مقدار batch_size ساخته میشود. یه خبر خوب، با این تابع میتوانید Batch و Mini Batch Gradient Descent را هم با تغییر مقدار Batch Size از یک به مقدار های بالاتر امتحان کنید.
Init_Weights

این تابع یک وزن اولیه رندم برای ما تولید میکند.
Compute_loss

این تابع نیز برای محاسبه Cost طبق همان فرمول ارائه شده استفاده می شود.
Mse

این تابع برای محاسبه Mean Square Error بر روی مقادیر پیش بینی شده و مقادیر واقعی استفاده میشود. ورودی اول مقدار های پیش بینی شده و ورودی دوم مقدار های واقعی هستند.
Predict

این تابع برای پیش بینی داده های جدید بر اساس پارامتر بدست آمده انجام میشود.
Train

در این تابع بر اساس فرمول های شرح داده شده، مدل آموزش داده میشود. ابتدا برای هر Batch مقدار loss محاسبه شده و بعد وزن ها آپدیت میشوند.
پارامتر ها
برای آموزش ما چند پارامتر را برای تنظیمات مدل تعیین کرده ایم.
- Batch_size : این مقدار برای تقسیم داده به همین مقدار، تعداد دسته استفاده میشود که ما برای Stochastic مقدار یک داده ایم.
- Epochs : این مقدار تعیین کننده تعداد تکرار و دفعات اجرای الگوریتم می باشد که ما 401 انتخاب کرده ایم.
- Lr : این همان نرخ یاد گیری است که ما 0.01 انتخاب کرده ایم.
نتیجه نهایی
نتیجه ای که میتوان گرفت این است که مقدار نرخ یاد گیری به شدت میتواند در یادگیری مدل تاثیر گذار باشد و اگر مقدار بالایی در نظر گرفته شود باعث میشود مدل Underfit شود یعنی به خوبی داده ها را یاد نگیرد. نتایج بدست آمده با مقدار پارامتر های توضیح داده شده به شرح زیر است.
مقدار MSE در هر Epoch بر روی داده های تست و در نهایت مقدار آن روی داده های Train :
Epoch: 0 | MSE Test: 15.129582669515761
Epoch: 100 | MSE Test: 9.390972122080267
Epoch: 200 | MSE Test: 9.390972122080267
Epoch: 300 | MSE Test: 9.390972122080267
Epoch: 400 | MSE Test: 9.390972122080267
MSE Train 8.339981046860567
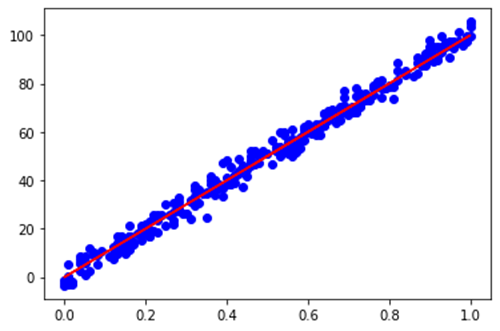
نمودار خط رگرسیون روی داده های Test:
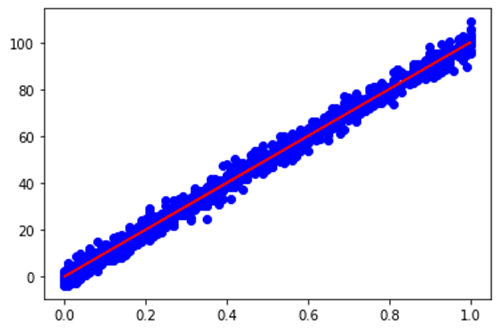
نمودار خط رگرسیون روی داده های Train:
وزن یاد گرفته شده نیز مقدار زیر می باشد.
[0.18501241]
نمودار توزیع داده های تست و خط رگرسیون هر دو روش closed form و stochastic gradient descent را هم در زیر میبینید که به خوبی روی هم قرار گرفته اند:

نمودار همگرایی MSE :

نمودار همگرایی وزن :
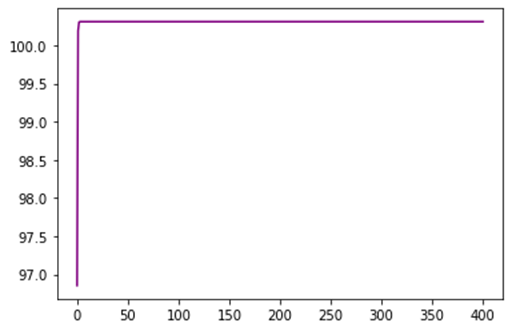
نمودار هم گرایی تابع هزینه:
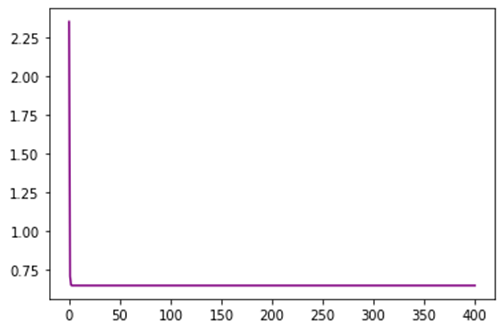
حداقل مقدار هزینه بدست آمده:
0.6516939975954287
برای دانلود فایل کد ها و دیتاست ها اینجا را کلیک کنید. برای رفتن به آموزش بعدی نیز اینجا و برای رفتن به آموزش قبلی اینجا را کلیک کنید.
امیدوارم این آموزش برای شما مفید بوده باشد. پیشنهاد میکنم که در تمرین ها و پروژه های درسی این کد ها را کپی نکنید چون انسان های زرنگ دیگری نیز وجود دارند.
همچنین میتوانید با تغییر دادن پارامتر ها الگوریتم را تست کنید و نتایج را مقایسه کنید تا درک بهتری از آن پیدا کنید.
خوب و خوش باشید.