در این پست قصد دارم بخشی از تجربیاتم را که کمتر جایی دیدم گفته شده باشد با شما در قالب یک سری keyword و یک نمونه پروژه به اشتراک بگذارم. نمیدانم در فارسی به عبارت Exploratory Data Analysis چه میگویند ولی ما اینجا به اختصار EDA خطابش میکنیم. در یک پروژه واقعی یادگیری ماشین، EDA بخش مهمی از کار محسوب می شود که شامل ایجاد نوتبوک هایی برای اکتشاف، شناخت و بررسی داده ها، پر کردن داده های گم شده، مهندسی ویژگی (Feature Engineering)، انتخاب ویژگی (Feature Selection) و توسعه مدل هست. بعد از آن پکیج کردن تمام این قدم ها در یک واحد و استقرار آن در محیط پروداکشن مهم ترین قدم محسوب می شود. تنها 53 درصد مدل هایی که توسعه داده می شوند در محیط پروداکشن استقرار می یابند. به همین دلیل دانستن راه حل ها و ابزار های MLOps، کار با کتابخانه هایی مثل FastAPI برای پیاده سازی یک سرور که درخواست ها را دریافت کرده و خروجی مدل را بازگرداند از مهم ترین مهارت هاییست که یک Machine Learning Engineer باید بلد باشد. اکثر این راه حل ها و ابزار ها توسط پلتفرم های ابری مثل AWS و GCP ارائه شده و تنها باید کار با آن ها را یاد بگیرید.
یکی از نیازمندی های یک مهندس یادگیری ماشین، داکیومنت کردن، رکورد کردن و دنبال کردن تمام مدل هایی هست که آموزش می دهد. اگر بخواهید بصورت دستی هر مدلی که روی هر نسخه از دیتاست و هر مجموعه پارامتری که ترین می کنید، خروجی آن را بصورت فایل های CSV و فایل های لاگ و غیره… ذخیره کنید یک بی نظمی بزرگ رخ میدهد. بعد از دو روز تقریبا فراموش میکنید هر فایل برای چه چیزی بوده یا خیلی دنبال کردنش سخت می شود. راه حل استفاده از ابزاری به اسم MLflow هست. با این ابزار شما به جای ذخیره اطلاعات ترین در فایل های جدا گانه از لاگ های MLflow برای ذخیره metadata مدل های خود استفاده میکنید. حتی میتوانید Schema ورودی و خروجی مدل خود را هم ثبت کنید. بعد از ترین های متعدد میتوانید پارامتر های استفاده شده را ببینید، بر اساس بهترین نتیجه مرتبشان کنید، یک ارزیابی و تحلیل از مدل های خود داشته باشید و بهترین مدل را از Model Registry انتخاب و استفاده کنید. این ابزار اصطلاحا برای Model Versioning استفاده می شود. ابزار های زیاد دیگری هستند که برای Dataset Versioning و Environment Versioning هم استفاده می شود و حتی Model Versioning هم در خود دارند. در این لینک و این لینک میتوانید این ابزار ها را بررسی کنید.
نیازمندی مهم دیگری که باید یک مهندس یادگیری ماشین به آن واقف باشد، ابزار های ساخت Pipeline هست. دانشمندان داده یا مهندسان یادگیری ماشین میتوانند یک مدل ML را برای پیشیبینی بر روی یک مجموعه داده آفلاین، با توجه به دادههای آموزشی مرتبط، پیادهسازی و آموزش دهند. با این حال، چالش واقعی ساختن یک مدل ML نیست، چالش ایجاد یک سیستم یکپارچه ML و به کار انداختن مداوم آن در تولید است. همانطور که در عکس زیر نشان داده شده است، تنها بخش کوچکی از یک سیستم ML در دنیای واقعی از کد ML تشکیل شده است. عناصر اطراف مورد نیاز گسترده و پیچیده هستند.
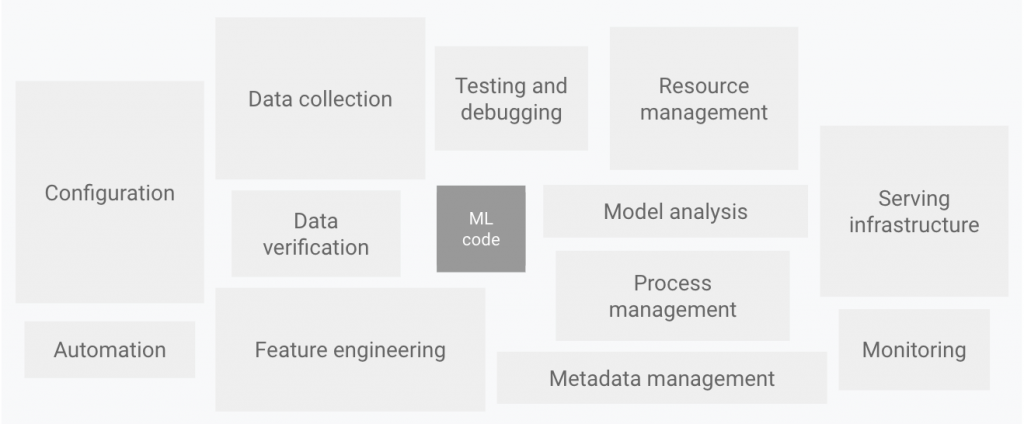
در این عکس، باقی سیستم از پیکربندی، اتوماسیون، جمعآوری دادهها، تأیید دادهها، آزمایش و اشکالزدایی، مدیریت منابع پردازشی، تحلیل مدل، مدیریت فرآیند و ابرداده، زیرساخت سرویس و نظارت تشکیل شده است. برای توسعه و راه اندازی سیستم های پیچیده مانند این، می توانید اصول DevOps را در سیستم های ML (MLOps) اعمال کنید. مراحل اتوماسیون تولید و استقرار مدل در سه level خلاصه می شود. در شکل زیر یک فرایند آموزش و استقرار مدل به صورت سنتی و کامل دستی یعنی level 0 را مشاهده می کنید.

و عکس زیر فرایند های MLOps Level 1 را میبینید.

پیشنهاد می کنم برای اینکه یک درک اولیه و کافی از این فرایند ها به دست بیاورید اول این مطلب را مطالعه کنید.
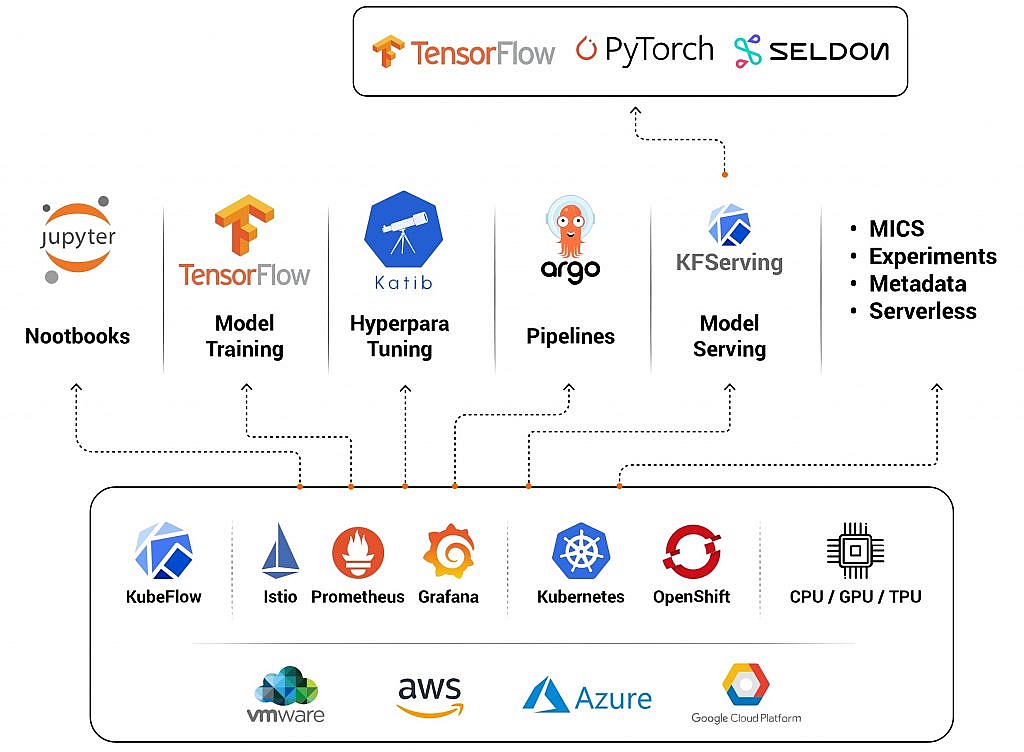
اگر از سرویس AWS استفاده میکنید عکس زیر برای هر بخش پایپ لاین تولید و عرضه مدل ابزار مربوط به آن در اکوسیستم AWS را معرفی کرده است. دقت کنید که این معماری برای تیم های نهایت 3 نفره است. برای تیم های بزرگتر ترجیحا این ویدئو را تماشا کنید.

بهترین ابزاری که برای ساخت پایپ لاین ها و همچنین مدیریت مقیاس پذیری (Scalability) پروژه استفاده کردم KubeFlow هست که بر پایه Kubernete هست. این که چطور پایپ لاین ها را با KubeFlow بسازیم، مقیاس پذیری پروژه را مدیریت کنیم (یعنی چه موقع سخت افزار اضافه یا کم شود یا از برنامه نسخه های دیگر اجرا شوند) و چطور روی پلتفرم های ابری مانند AWS آن را پیاده سازی کنیم خود یک مبحث بسیار گسترده است که به عهده خودتان میگذارم.
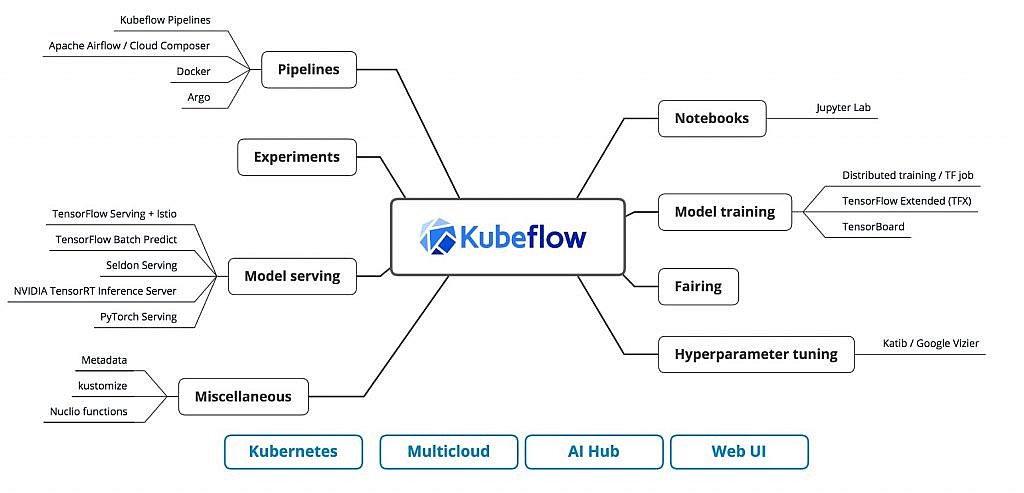
از TensorFlow Serving هم برای ساخت پایپلاین ها استفاده می شود ولی دیگرقابلیت مدیریت مقیاس پذیری را ندارد.
برای این که بتوانید خود را یک Senior Machine Learning Engineer بنامید، باید علاوه بر تجربه در طراحی و ساخت مدل، در زمینه استقرار مدل یعنی DeploymentX و MLOps هم دستی داشته باشید. درواقع بدون دانش MLOps، شناخت ابزار های Versioning، دانستن نحوه کار با پایپلاین ها، داشتن تا حدودی دانش Back-end Development، آشنایی با یک پلتفرم ابری مانند AWS SageMaker یا Google Cloud Platform ونحوه مقابله با چالش های مقیاس پذیری در بخش مختلف (از آماده سازی داده تا ساخت و ترین مدل و استقرار آن) نمیتوانید کاری پیدا کنید. پس از الان به دنبال برطرف کردن نقطه ضعف های خود باشید.
در این ریپازیتوری نیز یک نمونه پروژه ساخت و استقرار مدل با FastAPI را آموزش داده و چالش ها و قدم ها را با جزییات شرح داده ام.


